As a programmer myself, Pace-Trace was developed first and foremost with you in mind. Over the years, I have found trace files (and therefore Pace-Trace) to be extremely helpful to help build most of the program types I am asked to build at clients. Of all the programs, conversion modules are usually considered the most difficult, and therefore I will address my approach here first.
Building conversion programs
We could spend all day arguing the various methods of building the best conversion program. As a developer on conversion teams for eight implementations, however, this is an area where hopefully people can benefit from experience and keep the faith for a moment. Simply put: For most conversions, there is no faster way to build a conversion program than using Pace-Trace to help build SQR code for you. I will take you through the “quick and dirty” approach of building a conversion module in SQR from a SQL trace file, and end with some notes and comments regarding this choice
Step 1: Preparation
Get manual data (paper, printout, screenshot) prepared that resembles what could be used as a source to convert one transaction if this conversion was to merely be manually entered. Determine what pages will be used in PeopleSoft to enter this data. Typically this should be done with help from users of the existing system as well as functional owners of the new system. If this information is not available, perhaps it is too early in the implementation to consider developing a conversion module.
Step 2: Get the trace
- Turn on tracing
- Key the data into all the appropriate pages online.
As you key in the data, populate every field that might be sourced from an inbound file. Give every field a different value that could be sourced for a different place; for example, the “From Date” and “Start Date” may always be given the same value when they are keyed in, so these could be the same; however, specify a different value for every field that could have a different value, even if in most cases they do not. In addition to making each field distinct, take screenshots of each page to record which value was stored where.
- Click Save
- Open the resulting trace file in Pace-Trace.
Tip: Choose “File > Save As..” to name and save this trace file to a location with the rest of your documentation of this conversion. It will be useful to have this trace file stored for reference with the screenshots.
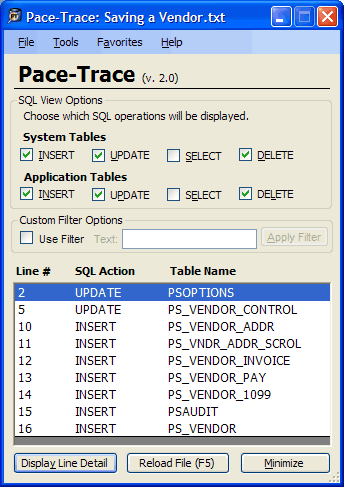
- Since you’re only interested in what was actually stored or modified, unselect the “Select” checkboxes in Pace-Trace.
The screenshot below displays the appropriate checkboxes selected with an example save of a Vendor:
Step 3: Analyze the trace
Look through the statements in Pace-Trace to determine exactly how the statements work together. Were some tables inserted into more than once? What was the correlation between what you entered on the page and what happened? You should have all this clear before continuing. If a relationship is confusing, go back and add multiple records to a particular page to verify any of your assumptions. You already have the screenshots of what you did, so you can use those to recreate the data with only one change — this makes it easy for you to get a clear cause and effect relationship.
Once you determine what tables are used for what pieces of data (for example, a vendor inserts into tables {x}, and each address inserts into tables {y}), integrate any logic requirements (for example, mark as a 1099 vendor if {z}) into a summary document for the entire conversion. This pseudocode can be used as the basis to code your SQR.
Step 4: Build the SQR
- Create an empty SQR module in your favorite text editor (Use a blank “template” SQR with common headers and #includes to make this faster.)
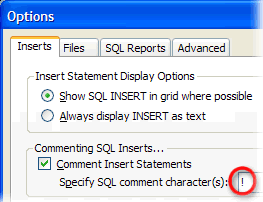
- Inside Pace-Trace, change the insert comment marks to use the SQR comment character of “!” instead of the default “–“. (Tools > Options, “Inserts” tab)
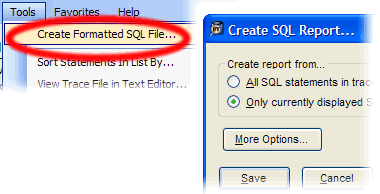
- Now, choose Tools > Create Formatted SQL File to quickly create a text file of all of these statements. When prompted, select to make a report out of “Only currently displayed SQL” and then click “Save.”
- You now have all the SQL formatted into one file. Take each SQL which will be used in your program and make a procedure with only that SQL, giving each procedure a standard name using {action}-{tablename} (e.g. Insert-Vendor). Click here for a simple example.
- In a development database, run this SQR just to make sure everything works as expected. Obviously, you may have to delete these same rows first if you plan to run this in the same database where these were originally inserted.
- In a copy of this SQR, use Find/Replace to change every instance of a value which you keyed-in online which should be replaced by an incoming data value and replace that value with an appropriate variable name. For example, if you entered “VENDOR_DESCRIPTION” into the “Descr” field online when you saved the vendor, then find this value and replace all occurrences with “$Vendor_Desc.” You can make this change with every text string easily. With date fields, you may need to check for several variants, depending on the date formatting used in the trace. This is when it is critical that you provided each field which will hold data from a converted source a unique value — if you keyed in the same value for two date fields which will be sourced from two areas, for example, it will be impossible to tell them apart in the trace, and therefore unexpected SQL statements which seem to not reference either field that include that date are impossible to populate correctly and safely.
- Now, build an “initialize” procedure to populate the fields from your external source, and include any necessary logic to populate values which depend on another value.
Step 5: Complete the Conversion Module
Once you have provided the basic structure of the conversion module to insert one record using SQL statements directly from the trace file, the rest of the conversion development process should be fairly standard: loop through each input record, populate the variables, and insert the record into the destination tables.
Additional Notes and Guiding Principles:
Approach conversion tasks thinking: Without any automated method, this data would have to be hand-keyed into the system. How would that be done? Figure this out, and automate it. In addition, what instructions would be provided to the person keying it in? It is these instructions which create the baseline logic for your application — if there would be a separate set of instructions to deal with a particular case, you are likely to have a specific part of your program with logic written to handle that.
You will likely need to trace more than one scenario to ensure you know how the application will store different types of data. For example, let’s say you are converting vendors and some of one type require you to fill in information on another page before you save it. You will want to have a full trace file created for both of these. Again, if someone manually keyed the data, then there would be unique steps for particular cases — trace each one of these.
For the fastest and most reliable conversion process, use a staging table to separate the effort involved in getting the data from the source and inserting into PeopleSoft tables. Assume roughly half of the columns in this staging table will be used to store the data from the source system, and the other half will be used to store PeopleSoft-ready data. Use one column to indicate a data error code, and another to indicate status (converted, processed, loaded, errored, etc.). A separate process should initially populate the source columns, and subsequently perform manipulations and validations on this data to popopulate the PeopleSoft ready fields. With all the data residing in this table, it is easy to then perform batch operations to determine such things as verifying that every value listed is contained within a prompt view, for example. Without a staging table, it would be difficult to argue for the speed and efficiency of using SQR over using a component interface.
For some types of activities, you will have to run a process (such as posting a transaction) as part of the process of entering the data. Turn on tracing for any associated batch process, and get the trace file from this and use it in conjunction with your online trace files. Depending on your particular scenario, it may make more sense to run any batch processes on all converted data after loading, instead of trying to imitate the batch process in your own module. This is the logical choice when the batch process can run across the entire dataset quickly and the complexity of the module is high. In other words, why build something which already exists? There is a larger looming question here, which is discussed below.
Why choose SQR as your conversion mechanism?
There are many options to choose from when performing a conversion of data with PeopleSoft, and using an SQR may not always be the best choice. For most conversions that requiring an automated approach, however, I have chosen SQR. Still, this is a choice for each developer, conversion manager, or technical lead involved with a conversion effort to consider.
Component Interface (and Spreadsheet Component Interface)
PeopleSoft delivers a great method of automating access to the online pages through Component Interfaces. Although this allows for extremely dynamic interaction with the application (as the app server is actually validating each entry as it is processed), the actual start to finish work on building a conversion program is typically much longer and tedious, and your eventual product is a conversion module that runs much slower. Depending on the amount of data you are converting, this can become a significant bottleneck throughout all areas of your project. There are some cases in which I have chosen to use component interfaces, however.
Not everything PeopleSoft stores into the database tables is as straightforward as merely tracing the SQL, however, and in those cases component interfaces can be a great help. For an inventory item conversion, for example, we found each save of the item involved adding the item to a tree that stores the items. If you have worked with the tree tables (pstreenode, pstreeleaf, etc.) before, you know adding or modifying those tables are not for the faint at heart. We made a pretty simple component interface to perform the load which let PeopleSoft handle updating the tree, and used the delivered spreadsheet component interface loader tool in this case. The load did take a while, but since this was largely static data, we did the operation ahead of time, and then migrated the item tables and the tree as a whole during cutover, making the final “conversion” almost instantaneous.
The validation afforded through using a CI is exceptional. Certainly, no one should consider an advantage of using SQR as a method of avoiding the validations performed online. Instead, use batch validation techniques (such as a staging table, discussed above) to catch errors across all incoming rows at one time than having the system validate each row independently.
Application Engine
Although Application Engine can run about as fast as SQR, I find the building of applications not nearly as well-suited for a conversion module. The code is easy to maintain, and has excellent access to component interfaces (although going the CI route would slow down execution considerably, of course). Since a conversion module will (hopefully) be only run once in the production environment, why have to perform steps such as security and migration around a process that will not (or should not) be in the production system anyway? Further, if the code is to be taken out, then how difficult is it to later open this code and determine what really happened during the conversion? An SQR, residing as a simple ASCII text file, is easy to merely archive with the rest of the project documentation, and available for anyone to open and view at a later time. Another factor against AE is the lack of knowledge existing developers from a legacy system have in this new tool — it presents a dramatic departure from most prior programs, where SQR code is largely readable with little ramp-up. As conversion development can span many months, coding in a language that is easier to hand between developers becomes a significant asset. Changes throughout the conversion process will frequently mandate building new code or even reverting back to an earlier approach. With archived versions of each SQR, handling these changes becomes much easier than with AE.
Data Loaders (Data Mover, SQL Loader, direct table moves, etc.)
In some cases, it may actually make the most sense to load the table data directly. This is unquestionably the fastest method of loading the data, but provides the least validation and logic. This method can be frowned-on by many technical managers, but given a simple enough task, it can limit the overall effort and streamline the conversion process in ways no other tools can.